Cách Netflix cá nhân hóa ảnh minh họa cho tiêu đề nội dung và tác động của nó

Mục tiêu chính của hệ thống đề nghị cá nhân hóa trên Netflix trong nhiều năm nay là đảm bảo những tiêu đề nội dung phù hợp cho từng tài khoản thành viên vào đúng thời điểm.
Với một danh sách gồm hàng ngàn tựa đề và dữ liệu người dùng đa dạng lên đến hơn 1 triệu tài khoản, việc cho ra một tựa đề phù hợp với từng cá nhân là thật sự cần thiết.
Tuy nhiên công việc đề nghị nội dung không chỉ dừng lại ở đó. Tại sao chúng ta nên quan tâm về những tiêu đề sẽ được đề nghị? Thế còn về những tiêu đề mới và lạ giúp khơi gợi hứng thú từ bạn thì sao? Làm thế nào mà họ thuyết phục được bạn chọn nội dung nào đó rất đáng xem qua? Câu trả lời là điều vô cùng quan trọng nhằm giúp những thành viên của chúng ta tìm ra nội dung tuyệt vời, đặc biệt là những tiêu đề kì lạ.
Một cách để giải quyết thách thức này là cân nhắc phần artwork hoặc hình ảnh mà chúng ta sử dụng để mô phỏng tiêu đề. Nếu ảnh đại diện cho tựa đề có khả năng thu hút ánh nhìn của bạn, thì ở đây vai trò của nó sẽ như một cánh cổng gợi mở điều gì đó về tựa đề, cho ta cái nhìn sơ bộ để xác định liệu đó có phải nội dung phù hợp với bản thân. Phần artwork có thể chứa hình ảnh diễn viên mà bạn yêu thích, khoảnh khắc thú vị như cảnh rượt đuổi xe, hay khung cảnh truyền tải nội dung chính của một bộ phim hoặc TV show. Nếu đặt đúng hình ảnh trên trang chủ tài khoản của bạn (và người ta có nói: một hình ảnh đáng giá ngàn lời), thì có lẽ, có lẽ thôi nhé, bạn sẽ thử chọn vào xem đấy. Đây cũng là điểm khiến Netflix trở nên thật sự khác biệt so với những kênh phương tiện truyền thông khác: chúng ta không có một sản phẩm mà là 100 nghìn sản phẩm khác nhau, mỗi thứ đều được cá nhân hóa về hệ thống đề nghị và hình ảnh.

Đây là cách thức mà thuật toán đề nghị truyền thống xem xét một trang.
Trong bài viết trước, chúng ta đã bàn về cách để xác định ảnh minh họa phù hợp với mỗi tiêu đề cho tất cả các thành viên. Với sự hỗ trợ của những thuật toán ngày càng được nâng cao, chúng ta càng nỗ lực tìm ra phần hình ảnh hoàn hảo nhất cho mỗi tiêu đề, ví dụ như Stranger Things, để thu hút nhiều sự quan tâm từ khán giả nhất. Tuy nhiên, bởi sự đa dạng trong sở thích và mức độ quan tâm khác nhau, sẽ tốt hơn nhiều nếu chúng ta có thể xác định phần thị giác tốt nhất cho từng thành viên để nhấn mạnh các đặc tính liên quan của nó đến họ?

Những hình ảnh khác nhau sẽ thể hiện tính bao quát của chủ đề,
vượt qua giới hạn của từng ảnh riêng biệt.
Hãy cùng nhau khám phá những tình huống mà tính cá nhân hóa hình ảnh minh họa trở nên hữu ích. Những thành viên khác nhau sẽ có lịch sử duyệt xem khác nhau. Bên trái là 3 tiêu đề mà một thành viên đã từng xem qua ở quá khứ. Bên phải mũi tên là minh họa mà thành viên có xu hướng lựa chọn xem khi được đề nghị.
Việc cá nhân hóa hình ảnh theo từng tài khoản được thể hiện khá rõ trong ví dụ về bộ phim Good Will Hunting. Quá trình cá nhân hóa này dựa vào những loại hình và chủ đề mà người xem có thể chọn. Một người dùng từng xem qua khá nhiều bộ phim lãng mạn có thể thấy thích thú với bộ Good Will Hunting nếu chúng ta cho họ thấy phần ảnh có hình diễn viên Matt Damon và Minnie Driver. Bên cạnh đó, người dùng từng xem nhiều hài kịch sẽ có xu hướng tìm đến bộ phim này nếu ảnh có mặt của Robin Williams, một diễn viên hài kịch nổi tiếng.

Một tình huống khác là về sức ảnh hưởng của dàn diễn viên có thể tác động đến việc cá nhân hóa sản phẩm thị giác cho bộ phim Pulp Fiction. Một thành viên xem nhiều bộ phim do Uma Thurman đóng vai sẽ thể hiện tương tác tích cực đến artwork của Pulp Fiction có mặt Uma. Trong khi đó, một người hâm mộ diễn viên Travolta sẽ thích xem Pulp Fiction nếu hình ảnh có sự góp mặt của John.

Tất nhiên, không phải tất cả mọi trường hợp cá nhân hóa đều rõ ràng và đơn giản như thế này. Vì thế chúng ta không xòe bàn tay ra mà đếm các nguyên tắc mà phải dựa vào dữ liệu để xác định hành động cần thực hiện tiếp theo là gì. Nhìn chung, việc cá nhân hóa hình ảnh sẽ khiến người xem chọn được tiêu đề phù hợp, từ đó cải thiện trải nghiệm người dùng.
Thách thức
Tại Netflix, chúng tôi ứng dụng tính cá nhân hóa và điều chỉnh nhiều khía cạnh của trải nghiệm người dùng bằng thuật toán, bao gồm những hàng nội dung xuất hiện trên trang chủ, tựa đề hiện diện trong hàng, bộ sưu tập, thông tin được gửi và vv… Mỗi yếu tố được cá nhân hóa đều có những thách thức riêng; việc cá nhân hóa phần ảnh cũng không là ngoại lệ và tồn tại nhiều thách thức. Một trong những khó khăn ấy là chúng ta chỉ có thể chọn một hình ảnh duy nhất đại diện cho mỗi tiêu đề. Ngược lại, phần cài đặt cá nhân hóa cơ bản sẽ cho phép chúng ta đưa ra nhiều lựa chọn cho người dùng, từ đó thu thập thông tin về sở thích của mỗi người.
Việc chọn lựa hình ảnh sao cho hợp lý đưa ta trở về bài toán gà và trứng: nếu người dùng chọn xem một tiêu đề, điều đó chỉ có thể được thực hiện từ hình ảnh mà chúng ta lựa chọn trình bày. Những gì ta muốn tìm hiểu là khi nào việc trình bày một phần artwork cho tiêu đề có thể tạo tác động đến hành vi xem (hoặc không xem) một tiêu đề và khi nào một người dùng sẽ xem nội dung (hay không) bất kể hình ảnh nào được trình bày. Do đó, cá nhân hóa hình ảnh là vấn đề quan trọng và thuật toán cần phải làm việc kết hợp cùng nhau. Tất nhiên, để có thể biết được cách cá nhân hóa này, chúng ta cần phải thu thập rất nhiều dữ liệu để xác định những yếu tố cho thấy những tác động tích cực của phần thị giác đến người dùng.
Một thách thức nữa là hiểu được tác động của việc thay đổi artwork đến người dùng cho một tiêu đề khi chuyển tiếp từ phần này sang phần khác. Việc thay đổi này có làm giảm mức độ nhận diện của tiêu đề đó, khiến việc tìm lại nội dung ấy bằng hình ảnh trở nên khó khăn hơn, ví dụ như nếu người dùng đã cảm thấy thích thú trước đó nhưng chưa hề xem qua? Hay thay đổi này có khiến cho người dùng cân nhắc chọn xem bởi mọi thứ đã được cải thiện? Rõ ràng, nếu chúng ta tìm được phần minh họa hoàn hảo hơn cho người dùng thì những thay đổi này vẫn khiến họ có chút bối rối. Việc thay đổi hình ảnh cũng dẫn đến vấn đề về kiểm soát vì rất khó để xác định hình ảnh nào thu hút được sự chú ý của người xem.
Thách thức tiếp theo là hiểu được tương tác hiệu quả giữa các artwork khác nhau trong cùng một trang hoặc session. Có thể sự xuất hiện của nhân vật chính trong một tiêu đề là thật sự hiệu quả vì nó nổi bật hơn những cái còn lại. Tuy nhiên, nếu mỗi tựa đề đều được gắn những hình ảnh tương tự nhau thì tổng thể trang sẽ không được thu hút cho lắm. Xem xét từng phần hình ảnh riêng lẻ là không đủ và chúng ta cần nghĩ về cách chọn đa dạng các hình ảnh cho nhiều tiêu đề trong một trang hoặc xuyên suốt một session. Hiệu quả của artwork đối với một tiêu đề có thể dựa vào những yếu tố (ví dụ như tóm lượt phim, trailer, v.v..) mà chúng ta trình bày. Do đó chúng ta cần có những lựa chọn đa dạng để mỗi hình ảnh có thể nhấn mạnh khía cạnh khác nhau mà người dùng có thể thấy thích thú của nội dung ấy.
Cuối cùng, việc cá nhân hóa cũng gặp thách thức về kĩ thuật, một trong số đó là trải nghiệm người dùng là thông qua thị giác nên chứa rất nhiều hình ảnh. Do đó, việc cá nhân hóa cho từng tài khoản có nghĩa là chúng ta phải làm việc với hơn 20 triệu yêu cầu mỗi giây mà không thể sao sát từng trường hợp một. Một hệ thống như vậy thật tình mang tính cứng nhắc: thất bại trong việc render hình ảnh UI làm giảm trải nghiệm người dùng. Thuật toán cá nhân hóa cần phải tương tác nhanh khi một tiêu đề nào đó xuất hiện, khiến tình huống trở nên bị động. Sau đó, thuật toán cần phải thay đổi liên tục để thích nghi bởi hiệu quả của phần minh họa có thể thay đổi cũng như các tiêu đề và sở thích của người dùng cũng vậy.
Phương thức ‘contextual bandits’ (bài toán bandit theo ngữ cảnh)
Nhiều bộ máy đề nghị của Netflix hoạt động dựa trên thuật toán máy móc học, hay machine learning. Thông thường, chúng tôi chọn một loạt dữ liệu về cách người dùng sử dụng dịch vụ, sau đó chạy thuật toán machine learning mới cho loại dữ liệu này. Tiếp theo, chúng tôi thử nghiệm thuật toán mới này và so sánh với hệ thống vận hành hiện tại thông qua bài kiểm tra A/B. Một bài kiểm tra A/B giúp chúng tôi đánh giá liệu thuật toán mới có tốt hơn so với hệ thống hoạt động hiện tại khi thử nghiệm với một nhóm người dùng bất kì. Các người dùng nhóm A sẽ được trải nghiệm với hệ thống hiện tại trong khi những thành viên B sẽ được áp dụng thuật toán mới. Nếu nhóm B cho thấy mức độ tương tác cao hơn với Netflix thì thuật toán mới sẽ được áp dụng cho toàn bộ dữ liệu người dùng hiện có. Tuy nhiên, phương pháp theo nhóm này phát sinh một vấn đề: nhiều thành viên không hề nhận được trải nghiệm tốt hơn trong khoảng thời gian dài. Điều này được minh họa trong biểu đồ dưới đây.
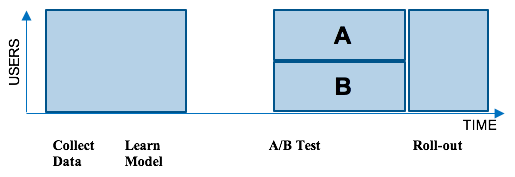

Để tránh điều này xảy ra, chúng tôi chuyển từ machine learning theo nhóm sang online. Đối với việc cá nhân hóa hình ảnh, chúng tôi sử dụng một khung online có tên contextual bandit. Thay vì phải chờ đợi hệ thống thu thập thông tin đầy đủ của một nhóm, cho thời gian để thích ứng với model và kết quả từ bài kiểm tra A/B để đưa ra kết luận, contextual bandit sẽ nhanh chóng cá nhân hóa artwork một cách tối ưu nhất cho tiêu đề của mỗi thành viên. Nhìn chung, contextual bandit là một phần của thuật toán học trực tuyến nhằm hạn chế chi phí thu thập thông tin cần thiết để tiếp thu và thích ứng liên tục với hệ thống khách quan nhằm ứng dụng model này vào từng trường hợp và tài khoản người dùng. Trong bài viết trước về việc chọn lựa hình ảnh không mang tính cá nhân hóa, chúng tôi sử dụng non-contextual bandit để tìm ra hình ảnh phù hợp bất kể context là gì. Về việc cá nhân hóa, mỗi người dùng được xem là một context riêng biệt bởi mỗi thành viên khác nhau sẽ có cách tương tác khác nhau với từng hình ảnh.
Tính chất nổi bật của phương thức contextual bandit là nó được thiết kế để giảm tối thiểu các lỗi và mức độ không hài lòng. Dữ liệu dành cho contextual bandit được thu thập thông qua quá trình dự đoán model ngẫu nhiên có cơ chế. Quá trình chạy ngẫu nhiên này có mức độ phức tạp khác nhau và chúng tôi gọi quá trình này là tìm kiếm khai thác dữ liệu. Số lượng hình ảnh minh họa dành cho mỗi tiêu đề nội dung so với số lượng tổng trên hệ thống sẽ cho chúng ta biết chiến lược khai thác dữ liệu nào sẽ được tiến hành. Với chiến lược ấy, chúng ta cần nhập thông tin về tính ngẫu nhiên cho mỗi lựa chọn ảnh. Điều này cho phép chúng ta tránh được xu hướng chênh lệch khi lựa chọn và đánh giá model offline một cách khách quan nhất.
Khai thác dữ liệu trên contextual bandit cũng dẫn đến một mức độ không hài lòng nhất định vì việc lựa chọn artwork theo người dùng có thể không chọn lấy bức hình tốt nhất theo dự đoán. Ảnh hưởng của hệ thống ngẫu nhiên này đến trải nghiệm người dùng (và ma trận) là gì? Với hơn 1 trăm triệu thành viên, mức độ không hài lòng khi khai thác thông tin thường rất thấp và được chia nhỏ cho tổng số lượng người dùng, mỗi thành viên sẽ đưa ra nhận xét về phần artwork cho một phần nhỏ trong tổng thể. Việc này sẽ giảm thiểu ảnh hưởng của việc khai thác thông tin trên một đơn vị thành viên, đây là một chi tiết quan trọng khi chọn phương thức contextual bandit để thúc đẩy những yếu tố chủ đạo trong trải nghiệm người dùng. Quá trình ngẫu nhiên hóa và khai thác thông tin theo phương thức contextual bandit sẽ không còn phù hợp nữa nếu ảnh hưởng của nó quá lớn.
Thông qua quá trình khai thác thông tin online, chúng ta sẽ có được dữ liệu theo mỗi thành viên, tiêu đề và hình ảnh. Hơn nữa, chúng ta có thể chủ động kiểm soát quá trình khai thác này để việc lựa chọn ảnh sẽ không thay đổi quá thường xuyên. Việc này sẽ khiến cho tính chất tương tác người dùng với một hình ảnh cụ thể được rõ ràng hơn. Bên cạnh đó, chúng tôi cũng xác định nhãn bằng cách phân tích chất lượng của tương tác ấy để tránh tạo ra model đề nghị hình ảnh “không phù hợp”: những hình ảnh khiến người dùng nhấn vào xem nhưng tạo ra tương tác chất lượng thấp.
Model training
Với model online này, chúng ta hướng dẫn cho model contextual bandit cách để chọn lựa phần ảnh tốt nhất cho mỗi tài khoản thành viên dựa trên context của họ. Chúng tôi thường có nhiều hình cho một tiêu đề nội dung. Để học model chọn lựa kiểu này, chúng tôi đơn giản hóa vấn đề bằng cách xếp hạng độc lập các hình ảnh cho một tài khoản với nhiều tiêu đề. Thậm chí khi đơn giản hóa thì chúng ta vẫn có thể biết được sở thích về hình ảnh của thành viên bất kì bởi vì với mỗi hình ảnh chọn lựa, chúng ta có nhiều thành viên hiện hữu nhưng không tương tác. Việc này có thể được lập trình để thực hiện dự đoán cho mỗi thành viên, khả năng chất lượng tương tác sẽ được cải thiện. Việc này có thể được kiểm soát thông qua sự nghiên cứu những mặt đối lập khác của contextual bandit với Thompson Sampling, LinUCB, hoặc phương pháp Bayesian giúp cân bằng việc dự đoán và khai thác thông tin.
Những tín hiệu tiềm năng
Với phương thức contextual bandit, phần ngữ cảnh thường được xem như một vector tính năng đầu vào cho model. Có nhiều dấu hiệu mà chúng ta có thể sử dụng làm tính năng cho vấn đề này. Cụ thể, chúng ta có thể nghiên cứu nhiều tính chất của một tài khoản thành viên thông qua những tựa đề nội dung mà họ xem qua, loại tiêu đề, tương tác của thành viên ấy với một tiêu đề, đất nước họ sinh sống, ngôn ngữ, thiết bị đang sử dụng, thời gian trong ngày và ngày trong tháng mà họ xem nội dung. Vì thuật toán chọn hình ảnh làm việc phối hợp với hệ thống đề nghị cá nhân hóa, chúng ta có thể sử dụng dấu hiệu liên quan đến nhận xét của thuật toán đề nghị đến một tiêu đề bất kể hình ảnh được sử dụng ở đây là gì.
Một nghiên cứu quan trọng nữa là một vài hình ảnh có thể vượt trội hơn so với các hình còn lại. Chúng tôi quan sát tỉ lệ chọn cho tổng thể hình ảnh khi khai thác dữ liệu, hiểu đơn giản là lấy số lượng xem chia cho mức độ ấn tượng. Nghiên cứu trước kia của chúng tôi về việc lựa chọn hình ảnh không mang tính cá nhân hóa sử dụng chênh lệch trong tỉ lệ chọn lựa để xác định cái thích hợp nhất. Với model cá nhân hóa theo ngữ cảnh mới, tỉ lệ chọn lựa vẫn có tầm quan trọng nhất định và việc cá nhân hóa vẫn cho ra kết quả chọn lựa trung bình so với model không cá nhân hóa.
Chọn lọc hình ảnh
Quá trình đưa phần hình tối ưu cho một người dùng là vấn đề chọn lọc để tìm ra hình ảnh tốt nhất từ những hình ảnh có sẵn. Khi model được thiết lập như trên, chúng tôi sử dụng nó để xếp hạng hình ảnh cho mỗi ngữ cảnh. Model sẽ dự đoán khả năng được chọn xem của hình ảnh ấy đối với một tài khoản người dùng. Chúng tôi phân loại các hình ảnh thông qua các khả năng ấy và chọn một cái có mức độ cao nhất. Đây chính là hình ảnh mà chúng tôi trưng bày cho người dùng.
Đánh giá hiệu quả
Offline
Để đánh giá thuật toán contextual bandit trước khi chạy trên hệ thống thực tế, chúng tôi có thể sử dụng kĩ thuật offline có tên replay [1]. Phương thức này cho phép chúng trả lời câu hỏi đối lập dựa vào dữ liệu đầu vào (Figure 1). Nói cách khác, chúng ta có thể so sánh điều gì đã xảy ra trước đó trong nhiều tình huống nếu sử dụng nhiều thuật toán khác nhau một cách khách quan.
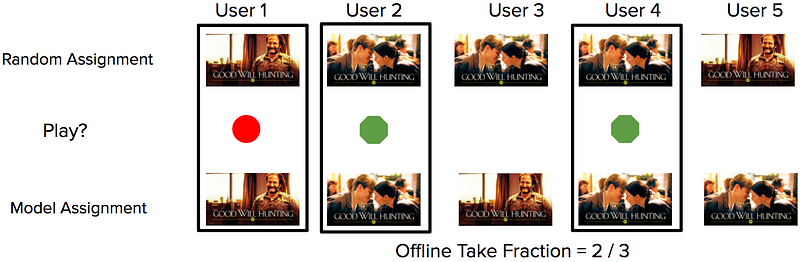
Với mỗi thành viên, một hình ảnh bất kì được chọn lựa (hàng trên cùng).
Hệ thống đưa ra cảm nhận và xác định liệu người dùng có chọn xem nó (vòng tròn màu xanh)
hoặc không (vòng tròn màu đỏ). Ma trận replay cho một model mới được tính thông qua việc kết hợp profile khi chọn lựa ngẫu nhiên và chọn lọc từ model là giống nhau (hình vuông màu đen) và đưa ra tỉ lệ – take fraction.
Replay cho phép chúng ta thấy được cách tương tác của thành viên ấy với tiêu đề nội dung nếu chúng ta trình bày theo giả thuyết hình ảnh được chọn lựa thông qua thuật toán mới thay vì cái đang sử dụng hiện hành. Đối với hình ảnh, chúng tôi quan tâm đến một vài ma trận, đặc biệt là tỉ lệ take fraction như trên. Sơ đồ 2 cho thấy tác động của phương thức contextual bandit đến việc tăng tỉ lệ take fraction trung bình trong tổng thể so với việc chọn lựa ngẫu nhiên hay non-contextual bandit.
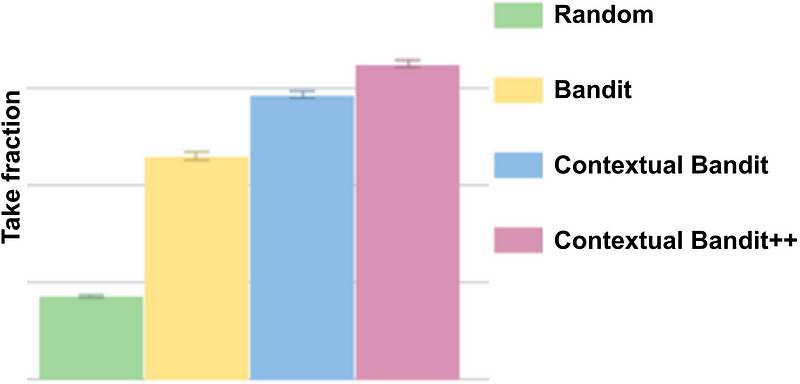
Phần Random (màu xanh lá) chọn hình ảnh theo cách ngẫu nhiên.
Phần thuật toán Bandit đơn giản (màu vàng) chọn hình ảnh có tỉ lệ take fraction cao nhất.
Thuật toán Contextual Bandit (xanh lam và hồng) sử dụng ngữ cảnh để chọn hình ảnh cho nhiều người dùng khác nhau.

Hài kịch dành cho những tài khoản thường xuyên xem các tiêu đề nội dung hài kịch.
Tương tự, loại phim tình cảm lãng mạn sẽ dành cho những tài khoản xem các tựa đề lãng mạn. Phương thức contextual bandit chọn hình ảnh Robin Williams, một diễn viên hài kịch nổi tiếng, cho những tài khoản có xu hướng chọn xem hài kịch và trình bày hình ảnh một cặp đôi hôn nhau cho những tài khoản có xu hướng xem thể loại lãng mạn.
Online
Sau khi thử nghiệm nhiều mô hình offline khác nhau và xác định những mô hình giúp tăng tỉ lệ replay, chúng tôi chạy bài kiểm tra A/B để so sánh giữa contextual bandit cá nhân hóa hứa hẹn nhất và bandit không có tính cá nhân hóa. Như dự đoán, việc cá nhân hóa tỏ ra hiệu quả và tạo ra thay đổi đáng kể trong ma trận chính. Đồng thời chúng tôi cũng nhận thấy sự tương quan giữa những gì được đo lường offline trong replay và những gì xảy ra online với các mô hình. Kết quả thu thập từ online cũng bật mí nhiều điều quan trọng.Ví dụ, việc cải thiện tính cá nhân hóa tăng đáng kể trong trường hợp người dùng chưa có tương tác nào trước đó với tiêu đề. Điều này là hợp lý vì chúng tôi nghĩ rằng hình ảnh sẽ trở nên quan trọng hơn khi phân tiêu đề ít quen thuộc hơn.
Kết luận
Với phương pháp này, chúng ta đã thực hiện bước đầu tiên trong quá trình cá nhân hóa khi lựa chọn ảnh minh họa cho hệ thống đề nghị. Điều này làm cải thiện cách người dùng khám phá nội dung mới vì thế chúng tôi đã áp dụng nó cho toàn bộ hệ thống! Đây là ví dụ cho việc áp dụng tính cá nhân hóa không chỉ đối với những gì mà chúng tôi đề nghị mà cách thức thực hiện quá trình ấy cho người dùng. Tiềm năng khai thác và cải thiện phương thức này là rất lớn, bao gồm phát triển thuật toán để giải quyết vấn đề cứng nhắc thông qua việc cá nhân hóa hình ảnh và tiêu đề mới nhanh nhất có thể, ví dụ như sử dụng các kĩ thuật máy tính.
Một tiềm năng khác là áp dụng các phương thức cá nhân hóa này cho các loại ảnh ta sử dụng và những yếu tố mô tả tiêu đề khác như bản tóm tắt, metadata và trailer. Một vấn đề nghiêm trọng hơn là làm sao để giúp các nghệ sĩ và nhà thiết kế xác định hình ảnh nào nên được thêm vào để khiến cho một tiêu đề trở nên hấp dẫn và mang tính cá nhân hóa hơn.
Tham khảo
[1] L. Li, W. Chu, J. Langford, and X. Wang, “Unbiased Offline Evaluation of Contextual-bandit-based News Article Recommendation Algorithms,” in Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, New York, NY, USA, 2011, pp. 297–306
- Bạn có biết, đây chính là chiến lược năm 2019 của Netflix
- Phương pháp “cá nhân hóa” trong thiết kế UX là gì?
Tác giả: Ashok Chandrashekar, Fernando Amat, Justin Basilico và Tony Jebara
Người dịch: Đáo
Nguồn: Medium
Cùng tác giả




iDesign Must-try
Netflix phát hành bộ toolkit mới, do koto studio thực hiện

Điểm tin nghệ thuật thế giới tháng 9/2021

Điểm tin nghệ thuật thế giới tháng 4/2021

Love, Death + Robots - Chuyện gì xảy ra trong bộ hoạt hình không dành cho trẻ em?

Netflix tung trailer Love, Death and Robots mùa 2 trên nhạc nền của phim kinh dị Hereditary

Bóc trần sự cám dỗ của tranh giả trong phim tài liệu ‘Made you look: A True Story about Fake Art’ trên Netflix
