Spotify: Những thuật toán đứng sau tính năng Discover Weekly thần thánh

Năm 2015, hơn 100 triệu người dùng Spotify khá hào hứng khi phát hiện ra playlist mới toanh có tên Discover Weekly.
Discover Weekly là tổng hợp danh sách 30 bài hát mà người dùng chưa từng nghe nhưng chắc hẳn sẽ yêu thích nếu có cơ hội thử qua, và đây quả thật là một tính năng kì diệu.
Tác giả: Sophia Ciocca
Tôi là fan cứng của Spotify, cụ thể hơn là Discover Weekly. Vì sao ư? Bởi nó cho tôi cảm giác được nhìn nhận và quan tâm. Họ hiểu rõ gu âm nhạc của tôi hơn cả những người tôi quen biết trước đây, và bản thân ngày càng phấn khích vì cảm giác hài lòng và độ chính xác ngày càng được nâng cao mỗi tuần. Những bản nhạc đúng chuẩn cứ xuất hiện khiến tôi ngỡ ngàng, tôi tự hỏi tại sao tôi lại yêu thích chúng nhiều đến vậy.
Kính thưa những người yêu âm nhạc, tôi xin được giới thiệu người bạn thân thiết:
Tôi không phải người duy nhất bị ấn tượng bởi tính năng Discover Weekly. Mọi người dùng đều điên cuồng vì nó, điều này khiến cho Spotify phải suy nghĩ lại và tập trung đầu tư nhiều nguồn lực hơn vào playlist sử dụng thuật toán này.
It's scary how well @Spotify Discover Weekly playlists know me. Like former-lover-who-lived-through-a-near-death experience-with-me well.
— Dave Horwitz (@Dave_Horwitz) October 27, 2015
At this point @Spotify's discover weekly knows me so well that if it proposed I'd say yes
— Amanda Whitbred (@amandawhitbred) August 18, 2016
Từ lúc Discover Weekly ra mắt năm 2015, tôi cứ muốn tìm hiểu cho tường tận về cách thức hoạt động của nó (Tôi là một fan hâm hộ nữ, lâu lâu lại tưởng tượng mình làm việc cho họ và nghiên cứu sản phẩm ở đó). Sau 3 tuần tra Google điên cuồng, tôi nghĩ mình đã biết được vài bí ẩn đằng sau.
Câu hỏi đặt ra là làm thế nào mà Spotify có thể chọn ra 30 bài hát mỗi tuần thích hợp cho mỗi người dùng như vậy? Hãy cùng nhau tìm hiểu về cách mà Spotify làm tốt hơn những nhà cung cấp dịch vụ âm nhạc khác về phương diện đề nghị bài hát nhé.
Lịch sử vắn tắt dịch vụ âm nhạc online

Trở về những năm 2000, Songza đột phá nền âm nhạc online bằng cách sử dụng công cụ tạo playlist thủ công cho người dùng. Đội ngũ gồm những “chuyên gia âm nhạc” sẽ tạo danh sách mà họ nghĩ rằng nó nghe ổn, và sau đó người dùng sẽ nghe theo playlist đó (Beats Music cũng thực hiện chiến lược tương tự). Việc chọn nhạc thủ công cũng tốt nhưng tất cả đều là sự lựa chọn của một cá nhân cụ thể. Do đó phương pháp này sẽ không chú ý đến gu âm nhạc của từng cá nhân.
Tương tự như Songza, Pandora là một trong những sản phẩm cùng thời trong lĩnh vực công nghệ số. Phương pháp thực hiện của họ có phần tiên tiến hơn chứ không đơn giản là gán mác cho từng bài nhạc thủ công. Một nhóm người sẽ nghe nhạc, đưa ra vài từ ngữ đại diện cho mỗi track, và gắn nhãn thích hợp. Sau đó, Pandora sẽ phân loại các nhãn và tạo ra một playlist gồm những bài hát nghe-có-vẻ-tương-tự.
Cũng trong khoảng thời gian ấy, agency tư duy âm nhạc từ MIT Media Lab có tên The Echo Nest được thành lập, đánh dấu sự đổi mới tiên tiến trong quy chuẩn cá nhân hóa âm nhạc. The Echo Nest sử dụng thuật toán để phân tích phần âm thanh và nội dung của bài hát. Điều này cho phép nó phân loại âm nhạc, cá nhân hóa các đề nghị, tạo playlist và phân tích.
Cuối cùng là Last.fm – vẫn còn tồn tại cho đến ngày nay, sử dụng quy trình có tên collaborative filtering nhằm tìm ra thể loại âm nhạc mà người dùng có thể thích.
Phía trên là những phương pháp các dịch vụ khác đã thực hiện để xây dựng hệ thống đề nghị bài hát, vậy Spotify đã làm việc ra sao? Làm thế nào Spotify có thể biết được gu âm nhạc của từng người dùng tốt hơn những dịch vụ đi trước?
3 mô hình đề nghị của Spotify
Spotify không ứng dụng một mô hình đề nghị riêng lẻ. Thay vào đó, họ kết hợp những phương pháp chiến lược tốt nhất từ các dịch vụ khác để tạo nên bộ máy hoạt động mạnh mẽ và độc đáo.
Để có được tính năng Discover Weekly, Spotify đã khai thác 3 mô hình đề nghị sau đây:
- Mô hình Collaborative Filtering (tương tự như của Last.fm) sẽ phân tích hành vi của bạn lẫn người dùng khác.
- Mô hình Natural Language Processing (NLP) sẽ phân tích phần kí tự.
- Mô hình Audio sẽ phân tích phần âm thanh thô.
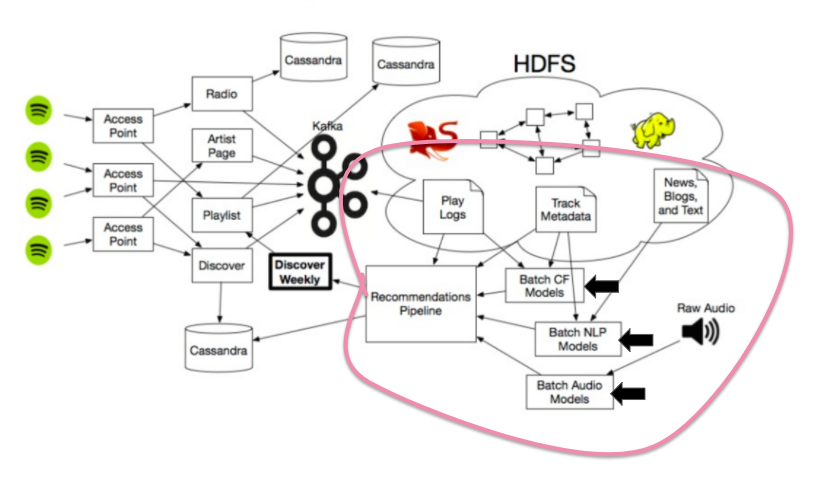
Nguồn ảnh:
Ever Wonder How Spotify Discover Weekly Works? Data Science,
via Galvanize.
Hãy cùng tìm hiểu cách vận hành của những mô hình đề nghị trên nhé!
Mô hình đề nghị #1: Collaborative Filtering

Khi nghe đến từ “bộ lọc tổng hợp”, mọi người thường nghĩ đến Netflix bởi đây là một trong những công ty đầu tiên ứng dụng phương pháp này cho mô hình đề nghị. Nó sẽ xem xét những bộ phim được đánh giá cao để đưa ra bộ phim đề nghị tiếp theo cho loại người dùng tương tự.
Sau thành công của Netflix, ứng dụng collaborative filtering nhanh chóng lan rộng và trở thành nền tảng cho những công ty khai thác mô hình đề nghị sau này.
Khác với Netflix, Spotify không có hệ thống đánh giá để người dùng đưa phản hồi và ý kiến cá nhân về bản nhạc vừa nghe. Thay vào đó, dữ liệu trên Spotify là những phản hồi thuần túy – cụ thể là số lượng các bản track và dữ liệu bổ sung, chẳng hạn như liệu người dùng có lưu lại bản track vào playlist cá nhân hay ghé thăm trang của nghệ sĩ trình bày bài hát đó.
Vậy thì thế nào là collaborative filtering, và cách nó vận hành ra sao? Tất cả sẽ được minh họa bằng cuộc hội thoại dưới đây:

bởi Erik Bernhardsson, ex-Spotify.
Mỗi người dùng đều có một danh sách ưa thích riêng biệt: người bên trái thích track P, Q, R và S trong khi người bên phải lại thích track Q, R, S và T.
Và sau đó collaborative sử dụng dữ liệu ấy:
“Hmmm… Cả hai bạn đều thích 3 track Q, R và S và sẽ được phân loại là những người dùng tương tự. Do đó, mỗi người sẽ có xu hướng thích track còn lại của nhau.”
Vì thế, hệ thống sẽ đề nghị người bên phải nghe thử track P – track nhạc duy nhất không được đề cập nhưng người bên kia lại thích – và đề nghị người bên trái nghe thử track T với lý do tương tự. Nghe có vẻ đơn giản ha?
Làm thế nào mà Spotify có thể thật sự ứng dụng concept ấy vào thực tế để đề nghị cho hàng triệu người dùng dựa vào dữ liệu từ hàng triệu người dùng khác?
Ma trận toán học và thư viện Python
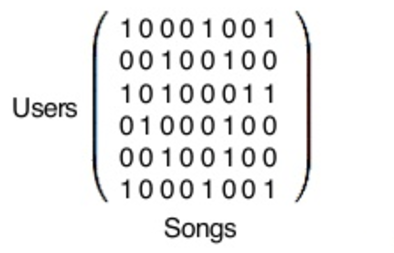
Trên thực tế, trong ma trận khổng lồ phía trên, mỗi hàng tượng trưng cho 140 triệu người dùng Spotify.Nếu sử dụng Spotify, bạn sẽ được đặt vào một hàng trong ma trận này – đồng thời mỗi cột sẽ đại diện cho 30 triệu bài hát trong dữ liệu của Spotify.
Sau đó, thư viện Python sẽ chạy và chúng ta có công thức tìm thừa số như bên dưới:
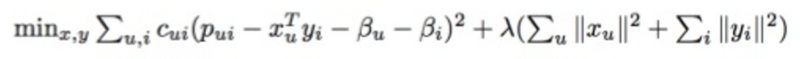
Khi quá trình kết thúc, kết quả trả về là 2 loại vector là X và Y. X là vector người dùng thể hiện cho gu âm nhạc của một cá nhân, Y là vector bài hát tượng trưng cho hồ sơ một bản nhạc.
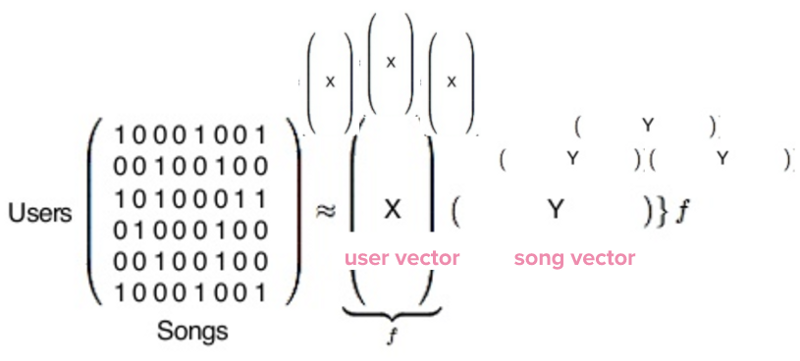
vector người dùng và bài hát.
Nguồn ảnh:
From Idea to Execution: Spotify’s Discover Weekly,
bởi Chris Johnson, từng làm tại Spotify.
Giờ đây chúng ta có 140 triệu vector người dùng và 30 triệu vector bài hát. Nội dung trong mỗi vector là những con số tưởng chừng như vô nghĩa nhưng lại cực kì hữu ích khi so sánh với nhau.
Để xác định gu âm nhạc của người dùng nào có đặc điểm tương đồng nhất với mình, mô hình collaborative filtering sẽ so sánh vector của tôi với những người dùng khác để chọn ra đối tượng khớp nhất. Điều tương tự sẽ diễn ra với vector bài hát Y: bạn sẽ có thể đối chiếu vector bài hát của mình với người khác và tìm ra bản nhạc thích hợp.
Mô hình collaborative filtering hoạt động khá tốt, tuy nhiên Spotify biết rằng họ có thể làm tốt hơn vậy với một loại mô hình khác, đó chính là NLP.
Mô hình đề nghị #2: Natural Language Processing (NLP)
Loại mô hình đề nghị thứ 2 mà Spotify đang ứng dụng là Natural Language Processing (NLP). Dữ liệu nguồn cho mô hình này, đúng như tên gọi, là các từ ngữ: dữ liệu liên kết, bài báo, blog và các dạng dữ liệu nội dung từ ngữ trên internet.

Natural Language Processing, hay còn gọi là khả năng thấu hiểu lời nói con người của máy tính, là phạm trù rất rộng và thường được khai thác thông qua phân tích cảm APIs.
Cơ chế đằng sau NLP không thể được gói gọn trong bài viết này, tuy nhiên nguyên lý cơ bản là: Spotify thường xuyên thu thập dữ liệu trên web, tìm kiếm các bài blog hay dữ liệu dạng từ ngữ để biết được cảm nghĩ của mọi người về một nghệ sĩ hay bài hát nào đó – những tính từ hoặc ngôn ngữ nào đó thường gắn liền với những nghệ sĩ và bài hát ấy cũng được đưa ra bàn luận cùng với những đối tượng khác.
Bản thân cũng không rõ cách mà Spotify chọn lựa và xử lý loại dữ liệu rời rạc này, tuy nhiên tôi có thể đưa ra một số phát hiện mới dựa trên cách Echo Nest đã từng ứng dụng nó. Họ kết hợp dữ liệu của Spotify thành một thứ gọi là “cultural vectors” hay “top terms.” Mỗi nghệ sĩ và bài hát chứa hàng ngàn những top terms luôn thay đổi hàng ngày. Mỗi term được đánh dấu mức độ quan trọng – có thể hiểu đó là cụm từ mà một người có thể mô tả về bài hát hoặc nghệ sĩ ấy.
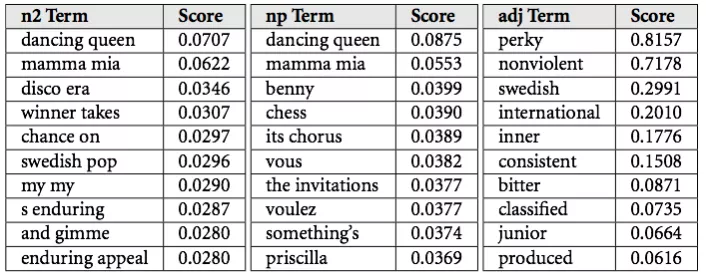
được Echo Nest ứng dụng.
Nguồn ảnh:
How music recommendation works — and doesn’t work,
bởi Brian Whitman, nhà đồng sáng lập của The Echo Nest.
Gần giống với collaborative filtering, mô hình NLP sử dụng term đi cùng với weight để xác định xem liệu 2 bản nhạc ấy có tương đồng hay không. Nghe hay nhỉ?
Mô hình đề nghị #3: Raw Audio
Câu hỏi trước tiên là:
Sophia, chúng ta đã có có kha khá
dữ liệu từ 2 mô hình đầu!
Tại sao lại cần phân tích audio nữa vậy?
Trước hết, việc có thêm một mô hình thứ 3 sẽ cải thiện độ chính xác của dịch vụ đề nghị bài hát. Tuy nhiên mô hình này có thêm một chức năng: khác với 2 mô hình trước, mô hình raw audio chú ý đến các bài hát mới.
Hãy lấy một bài hát mà bạn bè của bạn đã đăng tải lên Spotify. Có thể nó chỉ thu hút được 50 lượt nghe và do đó sẽ có một vài người nghe khác lọc ra nó. Nó cũng không được đề cập trên mạng, do đó mô hình NLP cũng không khả thi. May thay, mô hình raw audio không phân biệt giữa track mới và thịnh hành, vì thế bài hát của bạn bè bạn sẽ xuất hiện trong playlist Discover Weekly cùng với những bài hát thịnh hành khác!
Nhưng làm thế nào chúng ta có thể phân tích dữ liệu raw audio quá trừu tượng?
Câu trả lời là với sự giúp đỡ của mạng lưới cuộn – convolutional neural networks!
Đây là công nghệ tương tự được sử dụng trong phần mềm nhận diện khuôn mặt. Đối với Spotify, chúng được ứng dụng cho dữ liệu audio thay vì pixel. Dưới đây là ví dụ cho mạng lưới này:
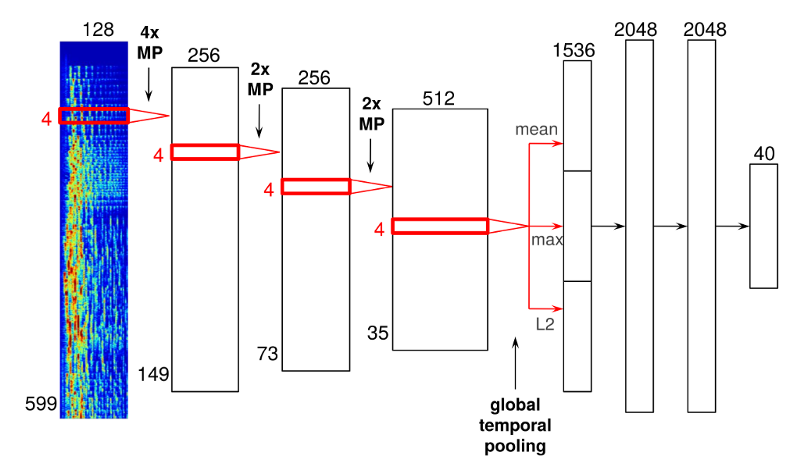
Recommending music on Spotify with deep learning,
Sander Dieleman.
Mạng lưới này bao gồm 4 lớp, 1 lớp dày bên trái và 3 lớp mỏng hơn bên phải. Dữ liệu đầu vào là khung audio theo thời gian và sẽ được kết nối để tạo thành ảnh phổ.
Khung audio sẽ đi qua các lớp ấy, và sau khi qua lớp cuối cùng, bạn sẽ thấy được lớp “tổng thời gian gộp”, ở đây sẽ liên kết xuyên suốt trục thời gian và mã hóa các số liệu thu thập được trong lúc bài hát được phát.
Sau phân đoạn ấy, mạng lưới sẽ cho ra kết quả phân tích bài hát bao gồm thời gian dự kiến, key, mode, tempo và độ lớn. Phía dưới là bảng phân tích dữ liệu của đoạn trích dài 30 giây từ bài “Around the World” bởi Daft Punk.
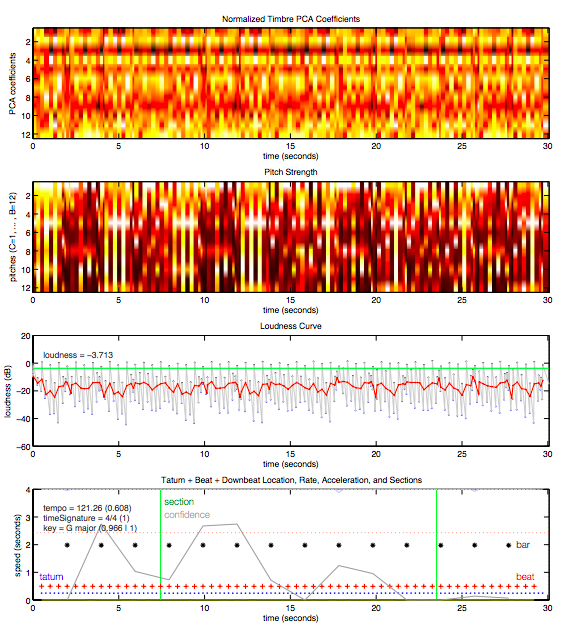
Việc tìm ra những đặc điểm chính của bài hát sẽ giúp Spotify hiểu được những tương đồng cơ bản giữa các bài hát, từ đó xác định đối tượng người dùng có thể thích nó dựa trên lịch sử nghe nhạc.
Chúng ta vừa đi qua 3 loại mô hình đề nghị nhạc chủ yếu của Spotify và cơ sở đằng sau của playlist Discover Weekly!
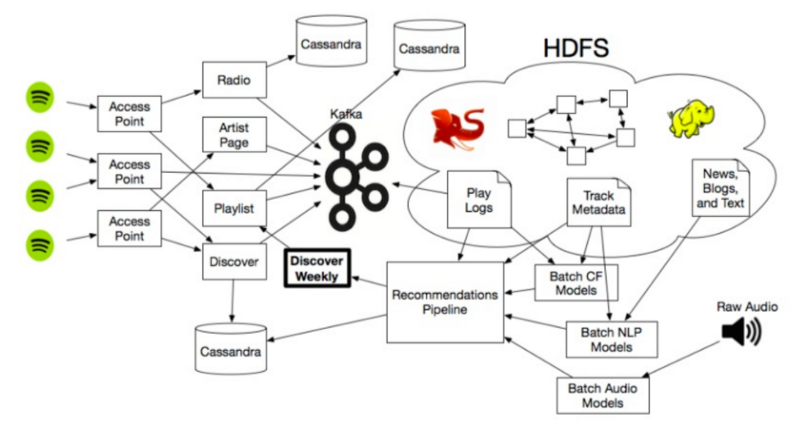
Dĩ nhiên là những mô hình này đều được tích hợp vào hệ thống lớn hơn của Spotify, nơi chưa lượng lưu trữ dữ liệu lớn và sử dụng khá nhiều Hadoop clusters để đo lường và khởi tạo chạy trên những ma trận lớn, bài viết âm nhạc online và một lượng lớn các tệp audio.
Tôi hi vọng bài viết sẽ cung cấp một số thông tin cần thiết và thỏa mãn sự tò mò của bạn. Tôi vẫn đang tìm tòi khám phá Discover Weekly để chọn ra bài hát yêu thích và am hiểu những quy luật ngầm bí ẩn trong đó. 🎶
Người dịch: Đáo
Nguồn: Medium
Cùng tác giả




iDesign Must-try

Điểm tin nghệ thuật thế giới tháng 06/2023

Hiếu Vũ: Âm nhạc & sự chuyển động, khoảnh khắc chủ chốt cho câu chuyện
Studio đứng sau sự nổi tiếng của các logo thương hiệu hàng đầu thế giới

Bộ nhận diện rung cảm như thanh âm của Sun Symphony Orchestra, dàn nhạc tư nhân Việt Nam

Tay trống của Red Hot Chilli Pepper và niềm vui mới với hội họa: ‘Có lẽ giờ tôi còn đam mê âm nhạc hơn so với trước đây’

Sound of Metal - Một bộ phim âm nhạc ‘yên lặng’
